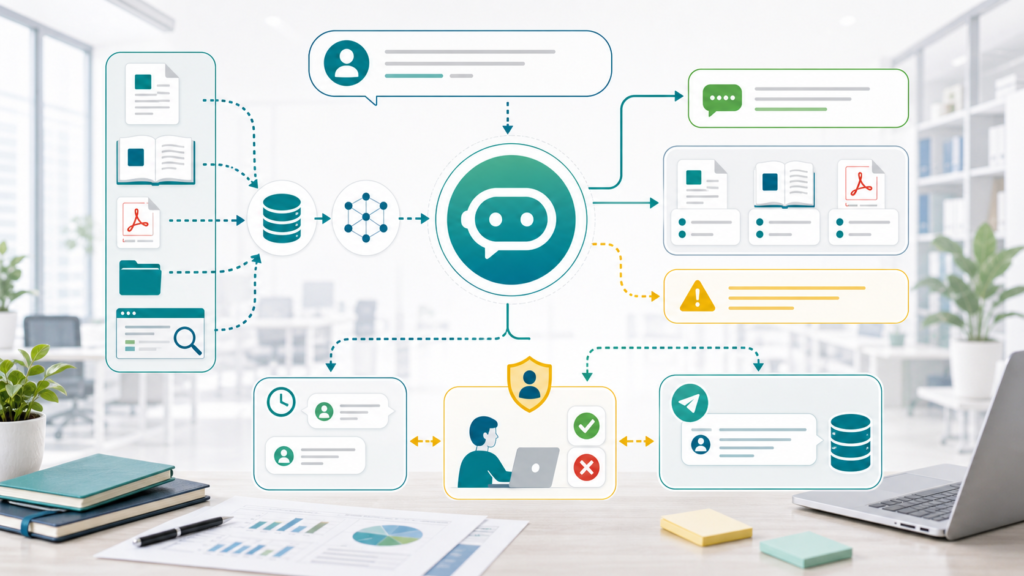
RAGチャットボットとは
RAGチャットボットとは、ユーザーの質問に対して、FAQ、マニュアル、商品資料、社内ナレッジ、過去の問い合わせ履歴などを検索し、その内容を根拠にして回答を作るAIチャットボットです。RAGは「Retrieval-Augmented Generation」の略で、生成AIが回答する前に関連情報を検索して補う考え方です。
通常のFAQチャットボットは、あらかじめ登録した質問と回答に近いものを返す仕組みが中心です。一方、RAGチャットボットは複数の資料から関連箇所を探し、質問文に合わせて回答を組み立てられる点が大きな違いです。問い合わせ対応、社内ヘルプデスク、営業資料検索、カスタマーサポートなど、情報が散らばりやすい業務と相性があります。
RAGの原型となる考え方は、検索で得た外部知識を生成モデルに組み合わせる研究として整理されています。たとえばRetrieval-Augmented Generationの論文では、知識集約型の自然言語処理で検索と生成を組み合わせる有効性が示されています。実務では、この考え方をFAQや社内資料に置き換えて使います。
FAQ型・ChatGPT単体・RAGチャットボットの違い
| 種類 | 得意なこと | 注意点 |
|---|---|---|
| FAQ型チャットボット | 決まった質問に対して、登録済みの回答を返す | 質問の言い回しや未登録の内容に弱い |
| ChatGPT単体 | 文章作成、要約、言い換え、一般的な説明 | 自社の最新資料や独自ルールを知らない |
| RAGチャットボット | 社内資料やFAQを検索し、根拠に沿って回答する | 参照データの整理、権限管理、回答検証が必要 |
| AIエージェント | 回答だけでなく、ツール操作や業務フロー実行まで行う | 承認設計、ログ、失敗時の停止条件が必要 |
最初から複雑なAIエージェントを作る必要はありません。問い合わせ対応では、まずRAGチャットボットで「回答案を作る」「参照元を出す」「不明な場合は人へ回す」流れを作るだけでも、対応品質とスピードを改善できます。
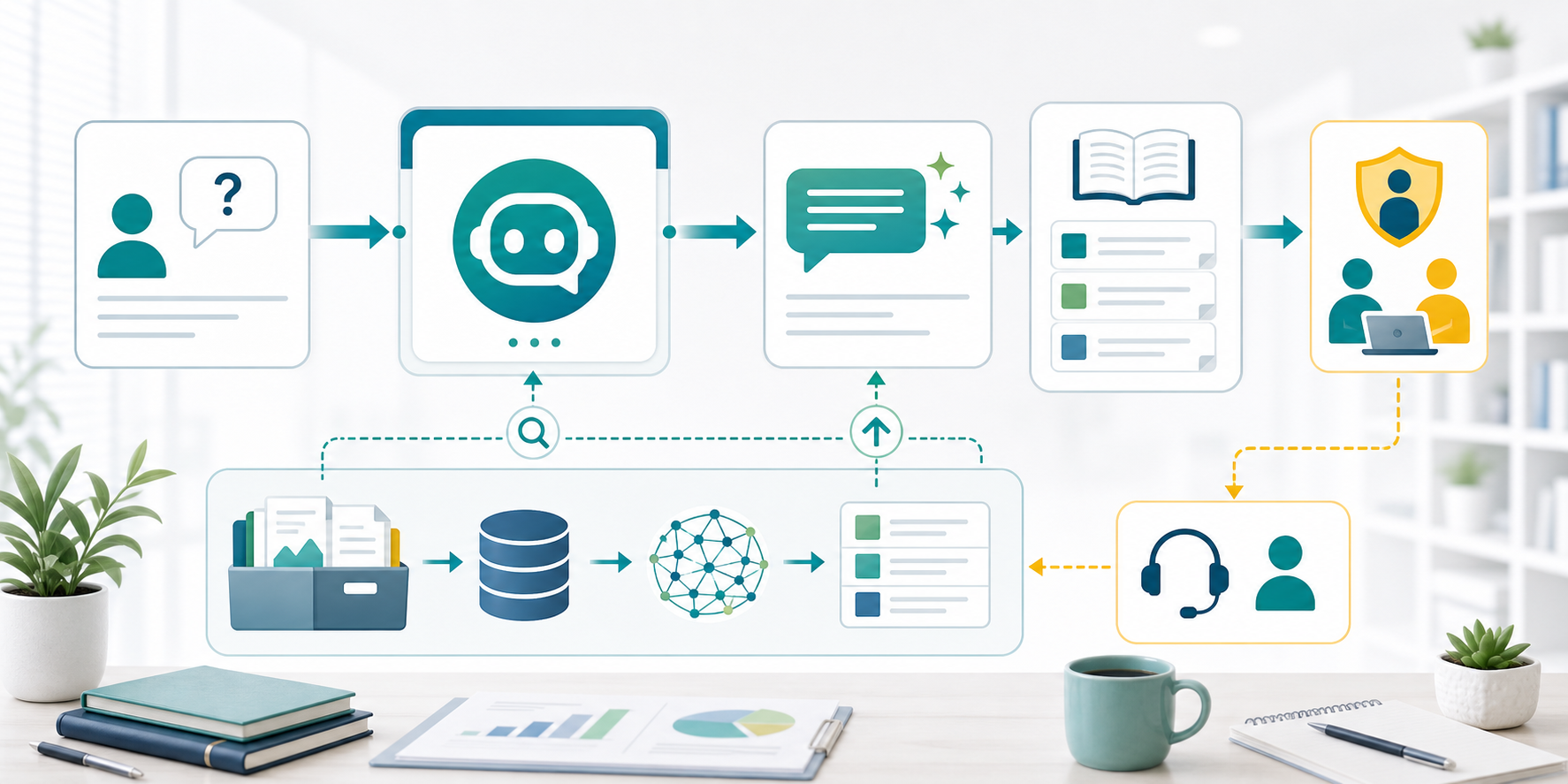
FAQ・問い合わせ対応で使う方法
RAGチャットボットをFAQ・問い合わせ対応に使う場合、目的は「AIに全部任せること」ではありません。まずは顧客や社内メンバーの質問に対して、正しい資料を探し、回答案を作り、人が確認しやすくすることを目指します。
特に中小企業では、FAQ、料金表、サービス資料、利用規約、業務マニュアル、過去のメール回答が別々の場所に保管されていることが多くあります。RAGチャットボットを使うと、担当者が毎回資料を探す時間を減らし、回答のばらつきを抑えやすくなります。
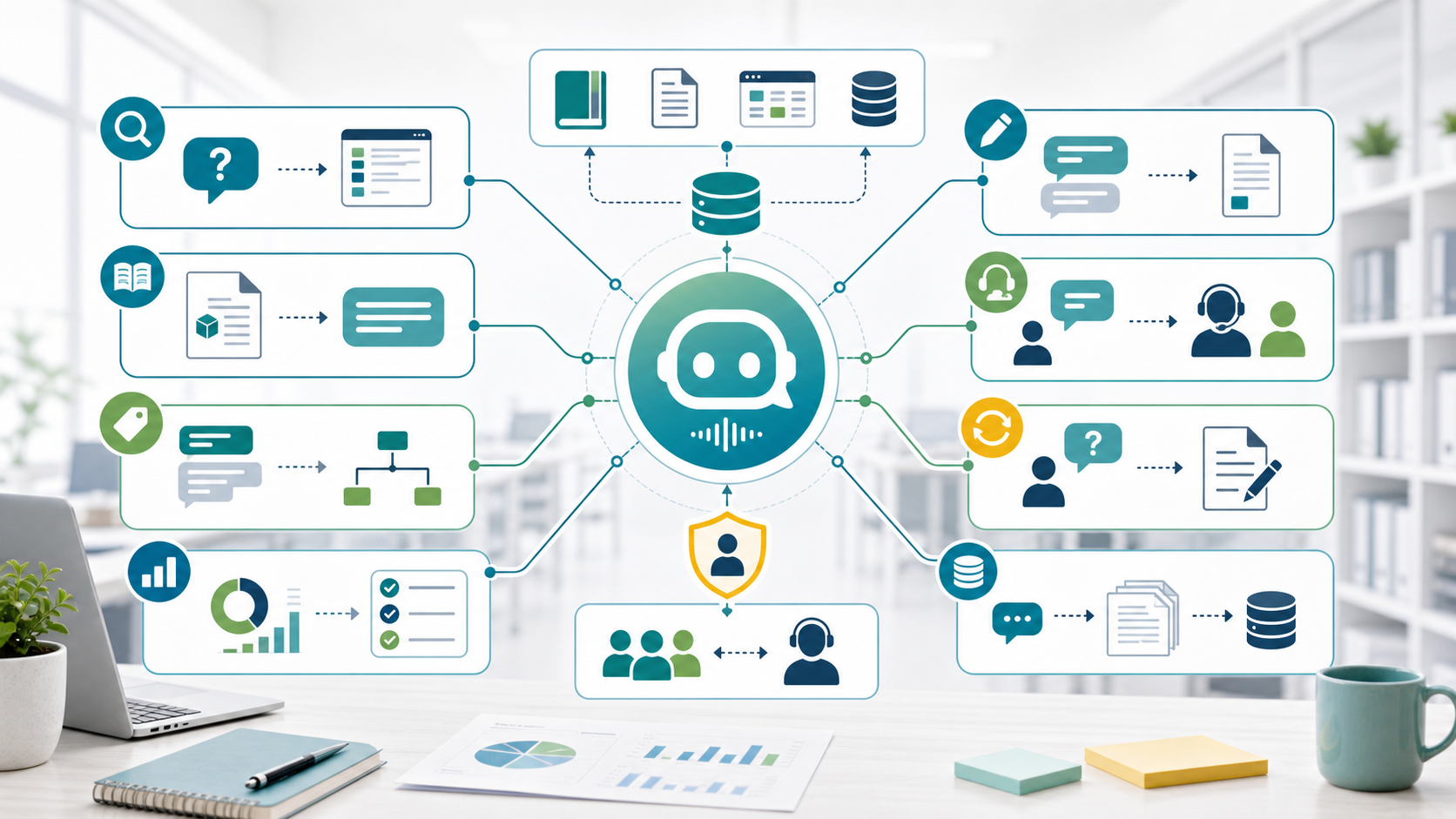
問い合わせ対応での活用例
| 業務シーン | RAGチャットボットでできること | 人が確認すべきこと |
|---|---|---|
| よくある質問への回答 | FAQから関連項目を検索し、自然な文章で回答案を作る | 回答が最新FAQに基づいているか |
| 料金・プランの質問 | 料金表やプラン資料を参照して説明文を作る | 個別見積もり、キャンペーン、契約条件 |
| 使い方・トラブル対応 | マニュアルから手順を抜き出し、順番に案内する | 障害情報、例外対応、顧客環境の違い |
| 問い合わせ分類 | 営業、サポート、請求、解約、クレームなどに分類する | クレーム、法務、個人情報を含む内容 |
| 返信文の下書き | 参照元付きでメール・チャット返信案を作る | 送信前の最終確認、表現、宛名、顧客事情 |
そのまま使えるプロンプト例
あなたは問い合わせ対応担当者です。以下の顧客質問に対して、検索されたFAQ・マニュアルだけを根拠に回答案を作成してください。根拠が不足する場合は推測せず、「確認が必要」と明記してください。回答には、参照した資料名、確認すべき点、担当者への申し送りも含めてください。
このように「参照資料だけを根拠にする」「不足時は推測しない」「人に確認してほしい点を出す」と決めると、RAGチャットボットを実務に入れやすくなります。顧客に直接自動返信する前に、まずは社内向けの回答支援として使うのが安全です。
RAGチャットボットの作り方
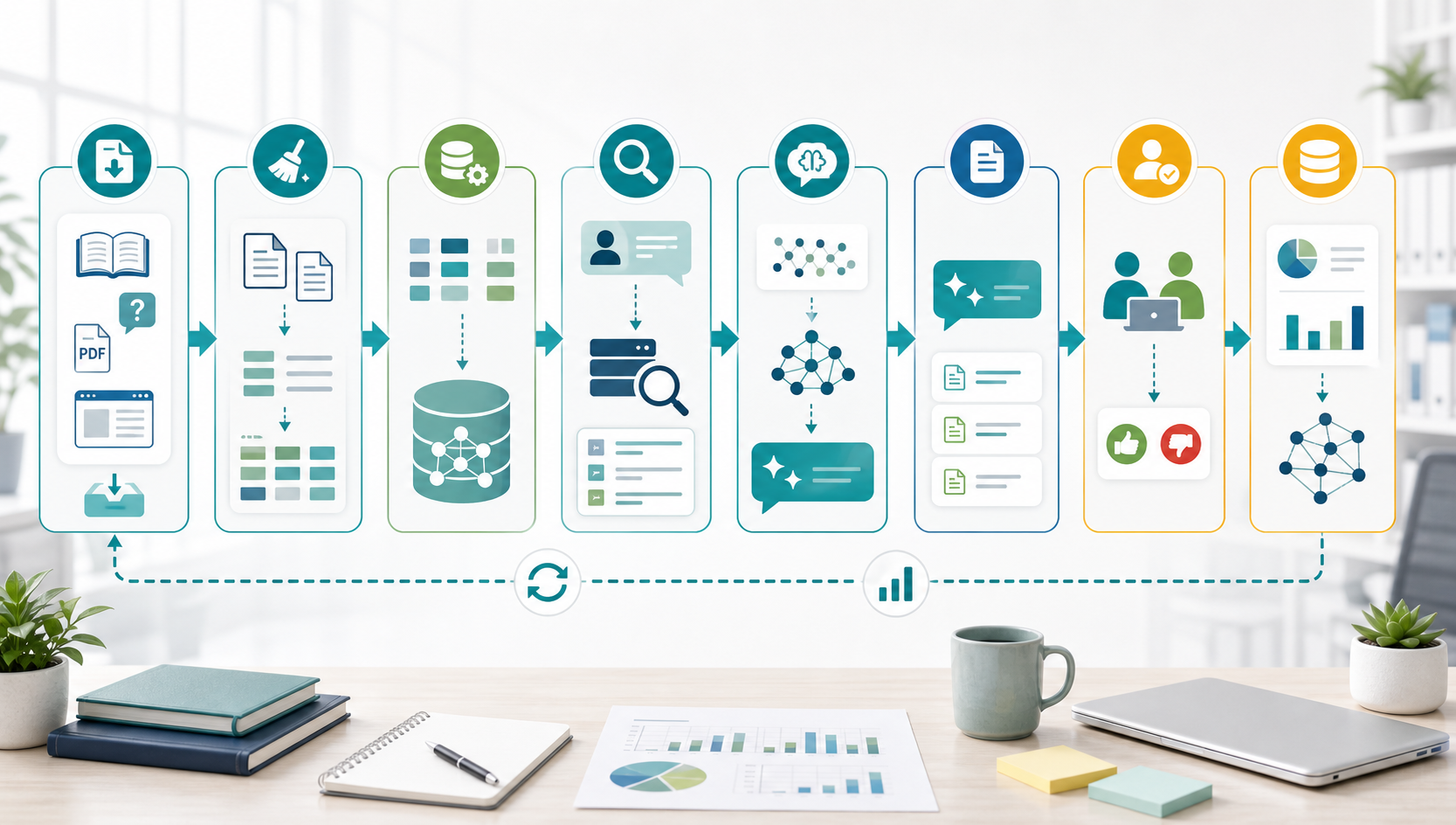
RAGチャットボットの構築で重要なのは、AIモデル選びよりも先に、参照させるデータを整えることです。古い資料、重複したFAQ、担当者ごとに違う回答、非公開情報が混ざっていると、AIの回答も不安定になります。
以下の順番で進めると、問い合わせ対応に使える形へ落とし込みやすくなります。
- FAQ、マニュアル、料金表、規約、サービス資料、過去の回答例を集める
- 古い情報、重複、誤情報、顧客固有情報、不要な個人情報を除外する
- 資料を質問単位・手順単位に分割し、カテゴリや更新日などのメタ情報を付ける
- 検索インデックスやベクトルデータベースに登録する
- ユーザー質問に近い資料だけを検索して取り出す
- 取り出した資料だけを根拠に回答案を生成する
- 参照元、回答できない条件、人へのエスカレーション条件を表示する
- ログを見て、FAQやマニュアルを継続的に更新する
構築時のチェック表
| 工程 | 確認すること | 成果物 |
|---|---|---|
| データ収集 | FAQ、資料、マニュアル、過去回答が揃っているか | 参照データ一覧 |
| データ整理 | 古い情報、重複、個人情報、非公開情報を除外したか | 投入用ドキュメント |
| 検索設計 | カテゴリ、更新日、部署、公開範囲で絞り込めるか | 検索ルール・メタ情報 |
| 回答設計 | 根拠表示、不明時の文言、担当者確認の条件があるか | 回答プロンプト |
| テスト | 正解質問、曖昧な質問、答えがない質問で検証したか | 評価ログ |
回答プロンプトの基本形
検索結果に含まれる情報だけを使って回答してください。根拠となる資料名を明記してください。検索結果に答えがない場合は、回答を作らず「担当者確認が必要」と返してください。契約、料金、返金、個人情報、クレームに関わる内容は必ず人の確認対象にしてください。
このプロンプトだけで完璧になるわけではありませんが、RAGチャットボットの事故を減らす基本ルールになります。特に顧客対応では、正しそうな文章よりも、根拠があるか、不明な場合に止まれるかが重要です。
導入時の注意点と運用チェックリスト

RAGチャットボットは便利ですが、導入して終わりではありません。FAQやマニュアルが古くなれば、AIの回答も古くなります。参照権限が曖昧だと、見せてはいけない社内情報を回答に含めるリスクもあります。
AI事業者向けの国内ガイドラインやNISTのAIリスク管理の考え方でも、AIシステムはリスクを把握し、運用中も継続的に管理することが重要とされています。問い合わせ対応に使う場合は、個人情報、契約条件、金額、クレーム、法務判断に関わる回答をAI任せにしない設計が必要です。
運用時のリスクと対策
| リスク | 起きやすい原因 | 対策 |
|---|---|---|
| 誤回答 | 検索結果が不十分、資料が古い、回答プロンプトが曖昧 | 根拠表示、不明時停止、定期テストを入れる |
| 古い情報の回答 | 料金表や規約の更新が反映されていない | 更新日メタ情報、期限切れ資料の除外、月次棚卸し |
| 機密情報の露出 | 参照データに社外秘情報が混ざる | 権限別インデックス、投入前レビュー、アクセス制御 |
| 個人情報の不適切利用 | 問い合わせ履歴や顧客情報をそのまま投入する | 最小限利用、マスキング、保存期間ルール、確認フロー |
| 現場に使われない | 回答が長い、参照元が見えない、既存業務とつながらない | メール・チャット・CRMと連携し、現場ログで改善する |
見るべきKPI
- 一次回答率:AIが回答案を出せた問い合わせの割合
- エスカレーション率:人の確認へ回した割合
- 正答率:テスト質問に対して根拠付きで正しく回答できた割合
- 対応時間:回答作成にかかる時間の削減幅
- FAQ改善数:ログから追加・修正したFAQの件数
- 再問い合わせ率:回答後に追加質問やクレームが発生した割合
FAQ
RAGチャットボットはFAQチャットボットより必ず優れていますか?
必ずではありません。質問が少なく回答が固定されている場合は、FAQ型のほうがシンプルで運用しやすいことがあります。資料が多い、質問の言い回しが多い、回答に文脈が必要な場合はRAGが向いています。
顧客に自動返信させてもよいですか?
最初はおすすめしません。まずは社内向けの回答案作成から始め、正答率、エスカレーション条件、承認フローを確認してから段階的に自動化します。
どのくらいの資料が必要ですか?
量よりも品質が重要です。少量でも、最新のFAQ、料金表、マニュアル、よくある回答が整理されていれば始められます。古い資料が大量にある状態より、少なくても正しい資料のほうが精度は安定します。
ノーコードでも作れますか?
簡易的なFAQ検索や問い合わせ分類であれば、ノーコード連携から始められます。ただし、権限管理、ログ、個人情報、複数システム連携まで含める場合は、要件整理と設計が必要です。



